What does the retrieval ecosystem look like in the age of agents?

This week I attended "Retrieval in the Age of Agents", a meetup organized by Qdrant and hosted at the Merantix AI Campus in Berlin.
The event brought together representatives from Qdrant, Haystack (deepset), Cognee, LlamaIndex, and n8n for a keynote and panel discussion about a question many of us are currently wrestling with:
As agents become more capable, what happens to retrieval?
The room was packed, with more than a hundred attendees and enough audience questions that the organizers couldn't get through all of them.
What surprised me most wasn't the discussion about vector databases or agents. It was how often the conversation came back to something much simpler:
Most retrieval problems are actually thinking problems.
TL;DR
The biggest takeaway wasn't about vector databases or agents, it was about asking better questions. Start from constraints and trade-offs, not technologies.
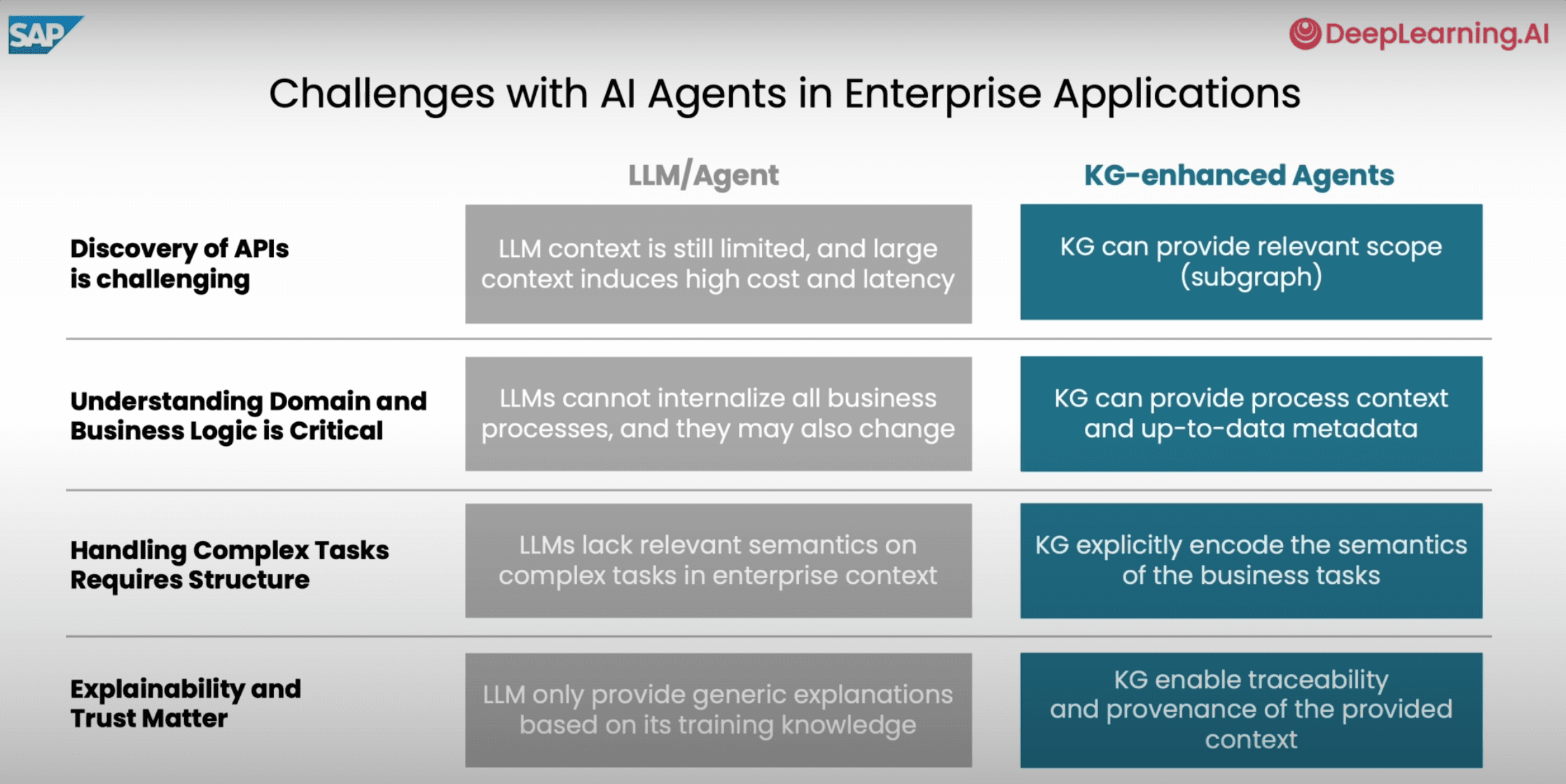
The retrieval ecosystem is becoming more specialized rather than more consolidated.
Qdrant is positioning itself as retrieval infrastructure, including offline and edge retrieval with Qdrant Edge.
Haystack by deepset is leaning into orchestration, observability, and enterprise-grade AI workflows.
Cognee treats agent memory as a dedicated systems problem rather than a prompting trick.
n8n argues that visual workflows remain valuable even in the era of AI-generated code because they are easier to understand, maintain, and share.
LlamaIndex is increasingly focused on document understanding, OCR, and preserving document structure rather than treating everything as plain text.
The emerging AI stack looks less like one platform doing everything and more like specialized layers for retrieval, orchestration, memory, automation, and document intelligence
The best retrieval advice wasn't about retrieval
The keynote by Qdrant CTO Andrey Vasnetsov contained my favorite takeaway of the evening.
He showed how people often ask technology questions too early.
Instead of asking:
Is grep all I need?
Ask:
Do I need indexing?
And even better:
What is the slowest and most expensive part (of my system) which might benefit from indexing?
Similarly:
Instead of asking:
Should I put my vectors into relational database?
Ask:
What guarantees do I need from vector store?
Or better yet:
What trade-offs am I ready to make for better performance?
The pattern appeared repeatedly throughout the event.
The most useful discussions weren't about choosing tools. They were about understanding constraints.
Retrieval architecture decisions become much easier once you understand what you're optimizing for: latency, cost, accuracy, observability, deployment constraints, or developer productivity.
The retrieval ecosystem is becoming more specialized
A few years ago, many retrieval products were trying to do everything.
What stood out during the panel is that each company now seems increasingly comfortable occupying a narrower role in the stack.

Qdrant: Retrieval infrastructure
Qdrant's positioning is straightforward: be the retrieval layer.
One particularly interesting area is Qdrant Edge, which enables retrieval scenarios that can run without a permanent internet connection, even on constrained hardware.
The implication is bigger than it sounds.
As AI moves into robotics, wearables, industrial devices, and edge computing environments, retrieval can no longer assume access to a cloud-hosted vector database.
The challenge then shifts elsewhere: embeddings.
Even if retrieval can run locally, query embeddings still need to be generated using a model compatible with the indexed data. In many edge scenarios, the embedding model becomes the real bottleneck rather than the retrieval engine itself.
Haystack: Orchestration with enterprise concerns
Haystack's positioning felt increasingly close to the orchestration layer often associated with LangGraph.
When I asked about the comparison, the answer wasn't that they were trying to be different from workflow frameworks. They acknowledged the overlap and emphasized areas such as:
enterprise readiness
observability
traceability
integrations with tools like Langfuse and OpenTelemetry
One interesting point raised during networking was that Haystack's open-source framework and enterprise offering are closely connected. The team sees reliability and quality as strategic priorities because improvements in one directly affect the other.
Cognee: Memory as a first-class problem
Cognee had perhaps the most distinctive perspective of the evening.
Their argument starts from a simple observation:
A single markdown file works surprisingly well as memory for a simple agent.
But that approach breaks down once you introduce multiple agents, multiple sessions, and long-running workflows.
Cognee approaches memory as a dedicated layer rather than treating it as a side effect of prompting.
They also frame memory through a cognitive-science lens, attempting to model different forms of memory rather than reducing everything to retrieval from a vector store.
Whether that becomes the dominant approach remains to be seen, but it highlights a broader trend: memory is becoming its own category rather than a feature inside agent frameworks.
n8n: The case for visual workflows
One question I asked was whether tools like n8n remain relevant when increasingly capable coding agents can generate applications and automations for us.
The answer was practical rather than philosophical.
Generated applications are still software that somebody has to maintain.
Visual workflows provide:
transparency
repeatability
easier debugging
easier collaboration
A workflow built in n8n can be inspected and modified by the broader team, while a custom application generated by an AI coding assistant may become another piece of software debt.
Their MCP tooling also points toward an interesting future where agents help create workflows rather than replace workflow systems altogether.
LlamaIndex: Structured documents still matter
LlamaIndex has increasingly focused on document understanding and analysis.
A key message from their representative was that not all documents should be treated as plain text.
If structure matters, retrieval alone may not be enough.
Tables, forms, invoices, reports, and other complex documents contain relationships that can be lost when reduced to chunks and embeddings.
Their focus on OCR and document analysis reflects this shift toward preserving and exploiting document structure rather than flattening everything into text.
The most honest answer of the night: "It depends"
During the panel, one question was whether agentic retrieval is actually reliable.
The answer, unsurprisingly, was:
It depends.
What was refreshing was that nobody tried to pretend otherwise.
The panelists represented different parts of the ecosystem, but there was broad agreement that reliability depends heavily on:
the use case
the evaluation strategy
the consequences of failure
the quality of the retrieval pipeline
In other words, "agentic" is not a substitute for engineering.
Evaluation is still the bottleneck
The strongest consensus across the panel emerged around evaluation.
Several themes appeared repeatedly:
Don't rely solely on LLM-as-a-judge.
Good evaluation requires good prompts and good datasets.
Start with domain experts.
Incorporate real user feedback as soon as possible.
Continuously grow benchmark datasets.
One observation resonated with my own experience:
- LLMs can help generate evaluation data, but in professional domains they are often useless.
What I left thinking about
The title of the event was Retrieval in the Age of Agents, but I left with a different impression.
For all the excitement around agents, memory systems, vector databases, and orchestration frameworks, the most recurring message of the evening was surprisingly old-fashioned:
There are no free lunches.
Every discussion eventually came back to trade-offs.
Better retrieval often means more infrastructure.
Edge deployment introduces model constraints.
Agent memory creates new complexity.
Evaluation requires human effort.
Flexibility often competes with reliability.
Today's architectural shortcut may become tomorrow's migration project.
Even the keynote repeatedly reframed technology questions into optimization questions.
Not:
Should I use X?
But:
What am I optimizing for?
That may be the most useful mindset for building AI systems today. The tools will continue to change rapidly. The trade-offs will remain.
Additional Resources
Event Resources
Qdrant YouTube Channel - The keynote and panel recordings are expected to be published here in the coming weeks.
People to Follow
Andrey Vasnetsov: Co-Founder of Qdrant, CTO.
Bilge Yücel: Senior DevRel Engineer at Haystack.
Clelia Astra Bertelli: Member of Technical Staff at LlamaIndex.
Marcel Claus-Ahrens: Automation Expert.
Vasilije Markovic: Founder at Cognee.
Evgeniya Sukhodolskaya: Senior Developer Advocate at Qdrant